Semantic-Analysis
书接上回,我们已经了解了Flex与Bison的特性,接下来,我们就可以使用二者完成词法解析、语法解析,并开始讨论Semantic-Analysis。
编译流程概述
编译过程包括词法分析、语法分析、语义解析、中间代码生成以及目标代码生成多个阶段。粗略地,可以将中间代码生成及之前阶段分为前端,其余分为后端。
词法解析
词法解析即将字符序列解析为token序列,便于后续语法分析。
词法解析基本原理
单词的构成一般符合正则语法,于是,可以使用正则表达式表达不同类型的单词。
词法解析过程
通过构造有限自动机,词法解析器可以自动识别出所有的单词,并将其转换为token。这一过程,现代往往使用手写完成,可以获取更高的性能。但出于便利,我们可以使用Flex作为辅助。
给定正则表达式,flex能够给出解析字符流,给出token/token序列的yylex函数,并完成一些附加动作。
语法解析
语法解析是继词法解析后,编译前端的又一阶段。
语法解析的基本原理
一般的编程语言,其文法都符合上下文无关文法,即:可以使用一个下推自动机识别。故,虽然上下文有关,乃至图灵文法的识别能力更强,但为了实现的简易与约束时间复杂度,我们还是上下文无关文法来实现。
一般的识别方法,分为:
- 自顶向下的推导
- 自底向上的移入/规约
具体的原理,相关书籍已作详细说明,此处不作赘述,仅需了解我们仰仗的Bison的yyparse函数的实现是基于移入规约即可。
语法树构造
一般的编译器的实现中,语法解析与语义分析往往同步实现,称作SDT。此处,为了降低难度,我们将其分为了两个部分来实现,其产物分别为抽象语法树与一般的中间表示——三地址码。
在语法解析,首先实现抽象语法树的构建。
这要求我们在Flex的附加动作环节生成叶结点,在Bison的附加动作生成非叶结点。其流程较简单,不作详细说明,有兴趣可以查阅文末的github仓库。
语义解析
语义解析,不仅仅从编程语言的文法角度来看待代码,而是从编程意图上去分析代码,这也正是生成等价的中间表示的基础。
语义解析的基本原理
语义解析的基础即SDD/SDT,将某些动作附加在语法分析的规约等行为上,在规约/推导的过程中,顺带解析出语义。
这其间,十分关键的一点便是构造符号表,将代码中对符号的定义、说明、调用等提取出来,并将其转换为符号表。解析的过程,即前序遍历语法树,收集符号,构造符号表,同时利用符号表中的现有内容进行类型检测、符号检测,并给出相应错误提示。
符号表构造
构造符号表,首先需要考虑其数据结构。
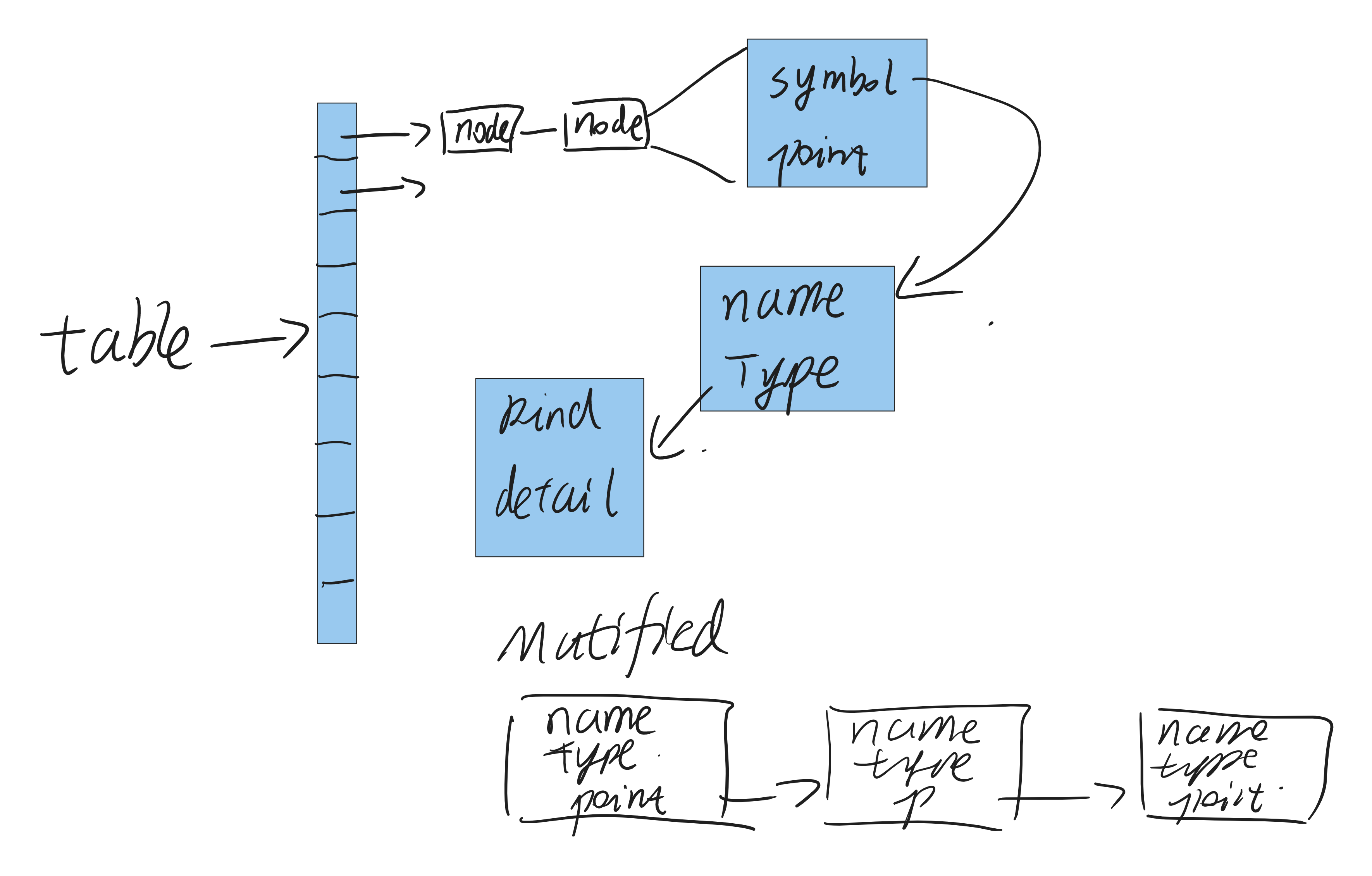
上图给出了我对符号表的一种简易实现
- table为一个结构体,带有一个hashtable与一些附加信息
- hashtable中则是hashlist与一些附加信息
- hashlist使用符号名的hash值来存储符号,并在符号外部包裹一层Node结构体,用于解决hash冲突(溢出方法/开方法)
- Symbol为一个结构体,带有name、type字段,分别表彰符号名和类型
- type为一个结构体,带有kind、detail字段,分别记述类型的种类和种类相关的详细信息,比如,基本类型就记述int/float;数组类型就记述数组元素类型与数组大小;结构体就结构体的tag与具体内容
- 此外,还存在一个multiField类型,用于记述一连串的符号,比如,一个结构体中的所有成员,或者一个函数的所有参数
暂时写到这,后续还会陆续补全其余内容。